
Hast Du eine alte Website und willst künftig mit WordPress arbeiten? Diese Beitragsserie zeigt Dir, wie Du den Inhalt anderer Content-Management-Systeme oder statischer HTML-Seiten in WordPress importierst.
Dieser Beitrag setzt voraus, dass Du Dich ein wenig mit HTML auskennst und Englisch verstehst – denn das benötigte Plugin mit seinen vielen Optionen gibt es nicht auf Deutsch. Ebenfalls wichtig: Es geht nur darum, den Content zu importieren. Das Design bleibt beim Import auf jeden Fall auf der Strecke. Das regelst Du nach dem Import über das WordPress-Theme.
Inhalte in WordPress importieren – so geht’s …
Der grundsätzliche Ablauf für den Import einer vorhandenen Website in WordPress setzt sich aus drei bis vier Schritten zusammen:
- Die bestehende Seite auf den Import vorbereiten
- Export der Website in statische HTML-Dokumente oder Grabben der Website mit HTTrack, wenn die alte Website in einem CMS liegt
- Importieren der HTML-Dokumente mit dem Plugin „HTML Import 2“ und die Nachbearbeitung: Formatierungen, Design-Anpassungen, Links und Bilder prüfen
Diese ersten drei Schritte wirst Du erfahrungsgemäß im Trial-and-Error-Verfahren mehrfach durchlaufen, bis es gut klappt. Denn insbesondere die Vorbereitung Deiner Seiten kann recht umfangreich sein. Da passieren leicht Fehler, die Du erst später aufgrund eines fehlgeschlagenen Imports erkennst.
Wichtigste Voraussetzung: Backups
Wichtigste Voraussetzung deshalb: Lege wie immer zunächst sowohl von der alten Website als auch von der neuen WordPress-Installation und -Datenbank ein Backup an, bevor Du Veränderungen vornimmst. Das wird Dir helfen, um nach einem fehlgeschlagenen oder unbefriedigenden Versuch noch einmal von vorne anfangen zu können.
Wie funktioniert das Plugin?
Zunächst ist zu „HTML Import 2“ anzumerken, dass die im Plugin-Verzeichnis von WordPress gelistete Version veraltet ist und mit den aktuelleren Versionen von PHP 7 nicht funktioniert. Es gibt jedoch eine Weiterentwicklung, mit der es dennoch klappt. Mangels Alternativen arbeiten wir deshalb damit. Lade das Plugin bei Github herunter und installiere es in WordPress unter Plugins – Installieren mit dem Button Plugin hochladen und lade die eben von Github heruntergeladene Zip-Datei hoch.
Das Plugin ist in der Lage, statische HTML-Dateien in WordPress zu importieren und wahlweise in Beiträge oder Seiten umzuwandeln. Damit das Plugin die inhaltliche Struktur dieser HTML-Seiten versteht, muss der HTML-Code bestimmte Elemente enthalten. Anhand dieser eindeutigen Tags erkennt das Plugin den eigentlichen Content sowie den Titel eines Beitrags.
Der wichtigste Schritt ist deshalb, die alte Website so vorzubereiten, dass das Plugin eine solche Struktur erkennen kann.
Vorbereitung
Für die Vorbereitungsarbeiten sind zwei Szenarien denkbar: Benutzt die alte Website ein Content Management System (CMS), solltest Du die im Folgenden beschriebenen Anpassungen über das Theme oder Template des CMS vornehmen.
Liegt die alte Website in Form von statischen HTML-Seiten vor, hilft für die Code-Anpassungen entweder ein seitenübergreifendes Suchen und Ersetzen oder Du musst die Seiten im ungünstigsten Fall manuell anpassen. Lade für beide Fälle die HTML-Dateien per SFTP vom Webserver auf Deine lokale Festplatte und bearbeite sie dort.
Seiten anpassen
Manchmal enthält der HTML-Code Deiner alten Website bereits eindeutige Markierungen für Titel und Content. Ist das der Fall, musst Du hier natürlich nichts anpassen.
Sieh‘ Dir also den alten Quellcode genau an. Da könnte zum Beispiel ein umfassendes DIV-Element mit id=“content“ sein, das jeweils den Beitragstext umschließt.
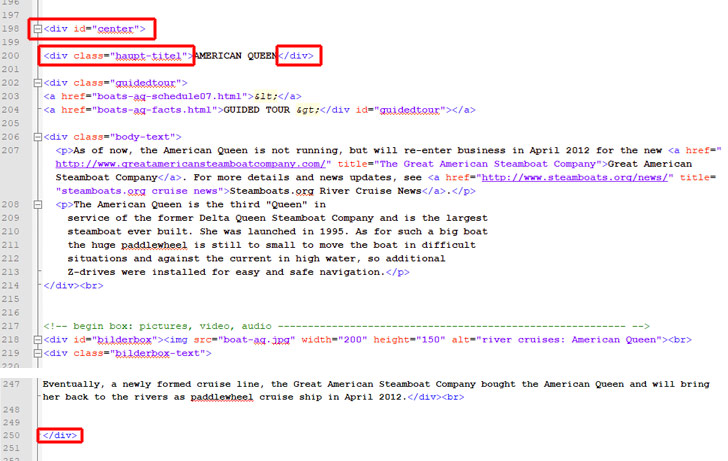
Wenn so etwas nicht vorhanden ist, musst Du es manuell ergänzen. Eventuell erlaubt das alte CMS das Editieren des Templates, sodass Du diese Elemente lediglich einmal an zentraler Stelle im Template einfügen musst.
Für manuelle Anpassungen im HTML-Code spart seitenübergreifendes Suchen-Ersetzen viel Zeit – ist aber nicht in jeder Situation möglich. Hilfreich ist dabei das kostenlose Notepad++ (Menü-Option Suchen – in Dateien suchen).
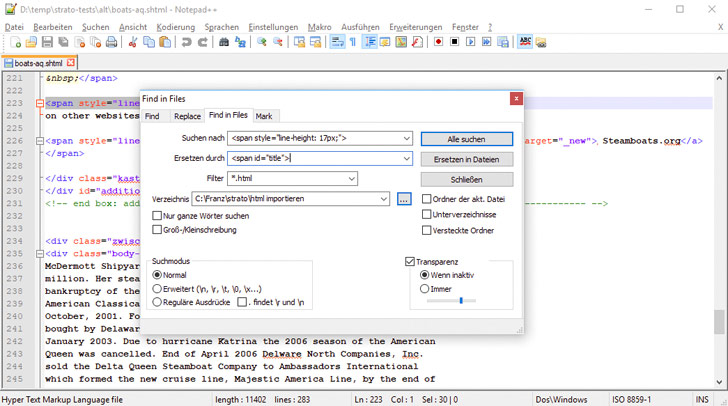
Suchen und Ersetzen
Mache Dich mit den vielfältigen Optionen des Plugins vertraut. Es bietet vielfältige Features, die wir hier vor allem der Übersichtlichkeit halber nicht im Detail besprechen. Wir konzentrieren uns auf die grundlegende Struktur der zu importierenden HTML-Dateien.
Zwingend nötig sind HTML-Tags zur Erkennung des Contents und des Titels, also beispielsweise <div id=“meininhalt“> … </div> für den Content-Bereich oder <h1> … </h1> für den Titel der jeweiligen Seite. Welche Tags das sind, spielt keine Rolle. Sie müssen nur eindeutig sein und dürfen in den zu importierenden HTML-Seiten nicht mehrfach vorkommen.
Beim Suchen und Ersetzen musst Du oft kreativ werden. Es lohnt sich aber, ein wenig zu tüfteln, um die Dateien optimal für den Import vorzubereiten. Backups nicht vergessen! Im Falle eines Fehlers stellst Du damit sehr komfortabel den Zustand vor dem Fehler wieder her.
Teil 2: So erzeugst Du statische HTML-Dateien für den Import
Besteht Deine alte Website bereits aus statischen HTML-Seiten, kannst Du diesen Schritt überspringen und direkt zum Importieren in Teil 3 übergehen. Wahrscheinlich nutzt Du aber auch bisher schon ein Content Management System (CMS), sodass Du statische Seiten daraus erst exportieren oder erzeugen musst.
Wichtig: Lege immer zunächst ein Backup der alten Website an, sodass Du alles wiederherstellen kannst, wenn in den kommenden Schritten etwas schief laufen sollte.
Im einfachsten Fall hat das CMS eine HTML-Export-Funktion. Lies dazu am in der Hilfe-Funktion oder Dokumentation des CMS nach, wie man die Export-Funktion nutzt. Wenn das CMS keinen HTML-Export bietet, musst Du ein wenig tricksen und den Content mit einer Desktop-Software grabben – also wie mit einem Browser abrufen und lokal speichern.
Website grabben mit HTTrack
Das beste Tool dafür ist die kostenlose Software HTTrack, die es für Windows und Linux gibt. Für Mac OSX existiert ein passendes Macport- oder Homebrew-Packages.
Die Software ruft die Seiten Deiner alten Website auf wie ein Browser und speichert die dabei erzeugten HTML-Dateien auf Deiner Festplatte. Wie Du eine Website mit HTTrack grabbst, findest Du in der folgenden Kurzanleitung, exemplarisch für Windows.
Website grabben mit HTTrack für Windows
- Starte WinHTTrack.
- Trage einen beliebigen Projektnamen ein.
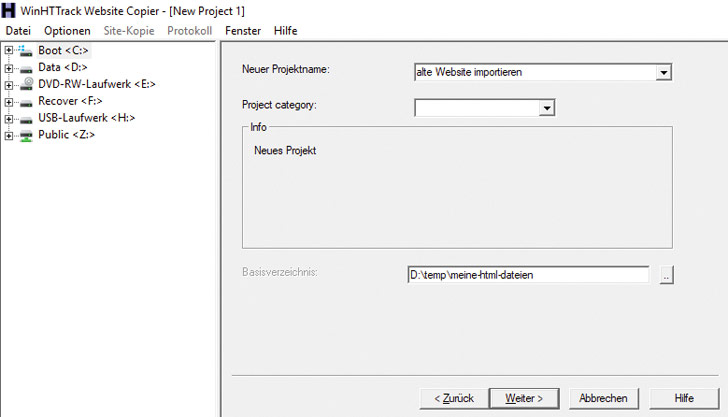
- Lege als Basisverzeichnis einen Ordner auf der Festplatte fest, in dem die HTML-Dateien gespeichert werden sollen.
- Klicke auf weiter.
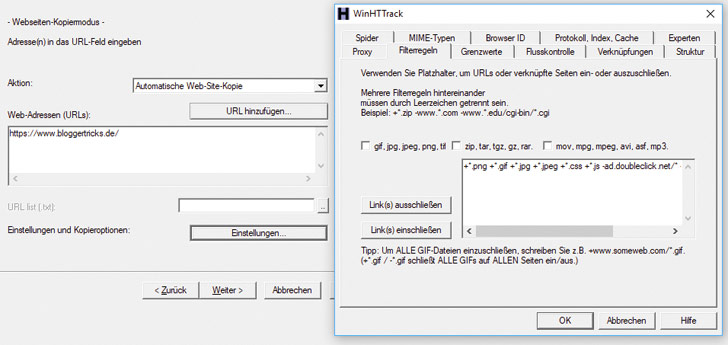
- Wähle die Aktion: Automatische Web-Site-Kopie.
- Gib unter Web-Adressen die URL der Homepage der zu grabbenden Website ein. Wenn Du möchtest, kannst Du stattdessen auch unter URL-List eine Text-Datei angeben, in der alle zu kopierenden Seiten einzeln als URLs aufgelistet sind. Das ist sehr nützlich, wenn der Grabber aus irgendwelchen Gründen mit den normalen Einstellungen. zu viel oder zu wenig Seiten grabbt.
- Klicke auf den Button Einstellungen.
- Wähle den Reiter Filterregeln.
Nach einem Klick auf den Button Einstellungen kannst Du im Reiter Filterregeln bestimmte Datei-Typen und Dateipfade explizit ein- oder ausschließen. Wie das geht, zeigt die Hilfefunktion des Tools direkt in dem entsprechenden Reiter. Gegebenenfalls musst Du hier ein wenig experimentieren, um das gewünschte Ergebnis zu bekommen. Sinnvoll ist, diverse fremde Domains auszuschließen, beispielsweise googlesyndication.com, wenn Du Adsense-Anzeigen auf der Website verwendest.
Tipp zum Vorgehen: Probiere das Grabben erst einmal mit Grundeinstellungen aus. Werden falsche oder zu viele Seiten erfasst, kannst Du im laufenden Betrieb abbrechen, die Filter verfeinern, ergänzen und es erneut probieren.
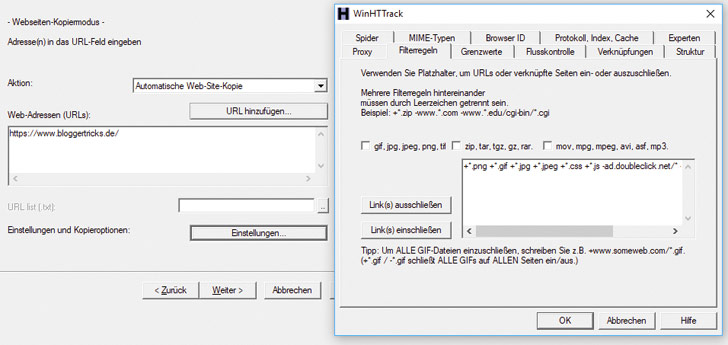
Wichtig: Im Reiter Struktur wählst Du Strukturtyp = „Site-Struktur (Standard)“ und deaktivierst das Häkchen vor „Keine externen Seiten“. Denn HTTrack klassifiziert alle URLs, die mit einem Domainnamen beginnen, als external, auch Deine eigene Domain – mit dem Ergebnis, dass ausschließlich die Startseite gegrabbt wird.
Bei Grenzwerte und Flusskontrolle kannst Du HTTrack nötigenfalls anweisen, nicht die volle Bandbreite Deines Internet-Zugangs fürs Grabben zu nutzen oder das Grabben auf eine bestimmte Zahl von gleichzeitigen Verbindungen zu drosseln.
Unter dem Reiter Browser ID wählst Du HTML-Fußzeile = none
Klicke jetzt auf weiter und dann auf Fertig stellen.Jetzt beginnt der Grab-Vorgang, der je nah der Größe Deiner Website eine Weile dauern kann.
Wenn HTTrack fertig ist, klicke auf Kopierte Seiten anzeigen. Dann siehst Du im Browser die lokale Kopie der Website, die Du eben gegrabbt hast. Kontrolliere genau, ob alles da ist, was Du brauchst. Achte darauf, dass Du beim Verfolgen von Links in diesen Dateien nicht versehentlich auf der Original-URL im Internet landest und daher fälschlicherweise annimmst, diese Seiten seien lokal vorhanden.
Teil 3: Content-Import mit dem WordPress-Plugin „HTML Import 2“
Jetzt kannst Du den entscheidenden Schritt in Angriff nehmen: den tatsächlichen Import nach WordPress.
Für den eigentlichen Import installierst Du das Plugin „HTML Import 2“ wie oben beschrieben und aktivierst es. Alle Optionen für den Import findest Du im WordPress-Backend unter Einstellungen – HTML Import.
Lege vor dem Import ein komplettes Backup der WordPress-Installation an. Dann musst Du nach einem unbefriedigend verlaufenen Import lediglich das Backup einspielen und kannst sofort einen neuen Versuch starten.
Alternativ kannst Du aber auch manuell alle zuvor importierten Seiten wieder löschen. Das ist aber nur dann eine brauchbare Alternative, wenn Du nur wenige Seiten importierst.
HTML-Dateien hochladen
Zuvor hast Du die zu importierenden Seiten bereits als statische HTML-Dateien vorbereitet. Diese lädst Du nun per SFTP inklusive eventueller Bilder, die ebenfalls importiert werden sollen, in ein Unterverzeichnis Deines Webspaces hoch. Die Verzeichnisstruktur muss dabei unverändert bleiben.
Der Verzeichnisname spielt dagegen keine Rolle. Die Dateien müssen nur unter derselben Domain abrufbar sein wie das WordPress-Blog, in das Du sie importieren willst.
Die wichtigsten Einstellungen
Das Plugin benötigt vor allem in den Reitern Content sowie Title & Metadata die Angabe, welche eindeutigen HTML-Tags den Content beziehungsweise Titel umschließen. Dafür ist ein Blick in den HTML-Quellcode der zu importierenden Dateien nötig. Aber den hast Du ja wahrscheinlich ohnehin schon intensiv bearbeitet, sodass Du Dich da auskennst.
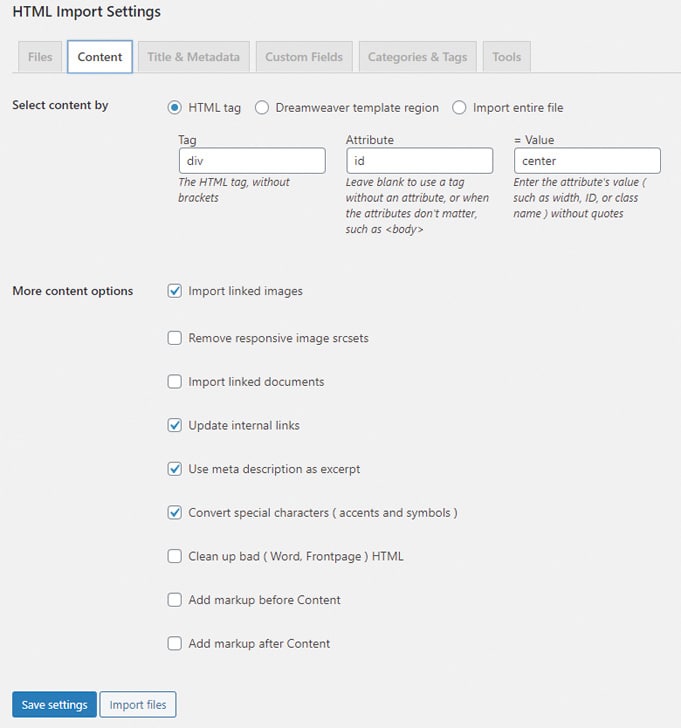
Ist also in Deinen HTML-Dateien der Seiten-Content beispielsweise mit <div id=“meininhalt“> … </div> umschlossen, trägst Du in den Plugin-Optionen im Reiter Content als Tag div ein, als Attribute id und als Value meininhalt. Genauso gehst Du im Reiter Title & Metadata für den Titel vor.
Sehr wichtig sind die Einstellungen im Reiter Files:
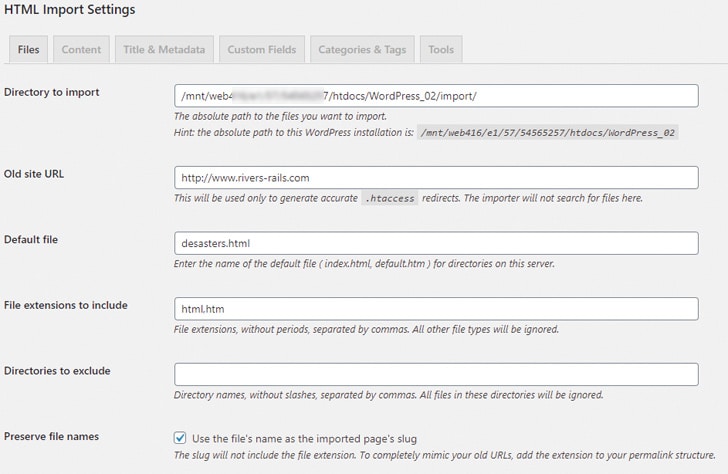
- Directory to import ist das Verzeichnis am Webserver, in dem die zu importierenden HTML-Dateien liegen. Das Plugin ermittelt den Server-Pfad automatisch, sodass Du den vorgegebenen Pfad lediglich um das Verzeichnis ergänzen musst, in dem die zu importierenden Dateien liegen.
- Old Site URL ist die URL, unter der Deine Website bisher zu finden ist – das kann auch dieselbe wie Dein neues WordPress-Blog sein. Das Plugin benutzt die URL, um korrekte Weiterleitungen für die .htacess-Datei nach dem Import zu erzeugen, damit Deine Beiträge weiterhin unter der bisherigen URL erreichbar bleiben beziehungsweise entsprechend weitergeleitet werden.
- Default file ist die HTML-Datei die bisher als Homepage fungiert hat.
- Files extensions to include beinhaltet alle Dateiendungen von Dateien, die beim Import berücksichtigt werden sollen, oft also: htm oder html, manchmal auch php, shtml oder Ähnliches.
- Preserve file names erhält die Dateinamen der Seiten Deiner alten Website, allerdings ohne Dateiendungen.
- Falls Du in der Nachbearbeitung Weiterleitungen komplett vermeiden willst und die Seiten unter exakt der gleichen URL abrufbar sein sollen wie vor dem Import, kannst Du das über die Permalink-Struktur von WordPress unter Einstellungen – Permalinks regeln. Aber die richtige Einstellung der Permalink-Struktur bei WordPress ist nochmal ein ganz eigenes Thema für sich.
Tipp: Wenn Du alte Seiten in ein schon bestehendes WordPress-Blog importierst, gehst Du auf Nummer sicher, wenn Du im Reiter Title & Metadata die Option Set status to auf draft setzt. Dann sind die importierten Beiträge nicht gleich öffentlich und Du kannst Sie noch bearbeiten oder korrigieren, bevor sie live gehen. Der Nachteil dabei: Du musst die Beiträge dann eben auch alle manuell veröffentlichen.
Spätestens wenn alle Plugin-Optionen gesetzt sind, klicke auf Save settings. Zum Import der HTML-Dateien klicke auf Import files. Nach erneutem Bestätigen der Import-Quelle startet der tatsächliche Import mit Klick auf Submit.
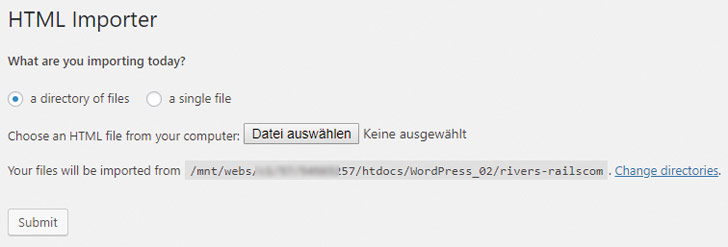
Nacharbeit: importierte Seiten prüfen und anpassen
Bevor Du anfängst, die importierten Beiträge oder Seiten zu bearbeiten: Kontrolliere, ob der Import so funktioniert hat, wie Du Dir das vorgestellt hast. Wenn nicht, spiele das Backup ein und probiere es mit entsprechend veränderten Einstellungen noch einmal.
Was nach dem erfolgreichen Import kommt, kann recht aufwändig sein. Denn das Plugin importiert lediglich den Inhalt der Seiten, behebt aber keine Fehler im HTML-Code oder der Content-Struktur, die dort schon vorhanden waren. In vielen Fällen wirst Du daher jede einzelne importierte Seite in WordPress öffnen und überarbeiten müssen. Ein HTML-Validator wie der von W3C oder Freeformatter kann Dir dabei helfen, HTML-Syntaxfehler zu finden.
Anpassungen, die alle importierten Seiten betreffen, hast Du idealerweise schon vor dem Import mit dem oben beschriebenen Suchen-und-Ersetzen-Verfahren vorgenommen. Wenn nicht, gibt es mit SearchReplace von Inpsyde aber auch ein gutes WordPress-Plugin für Suchen-und-Ersetzen-Operationen innerhalb Deiner Beiträge.
Die Sache mit den Permalinks
Gut für Deine Leser und Deine Internetpräsenz ist es, wenn die neuen Seiten weiterhin unter der alten URL erreichbar sind. Am wenigsten aufwendig ist es hierbei, mit permanenten Weiterleitungen zu arbeiten. Für das Google-Ranking ergeben sich daraus keine Nachteile.
Das Plugin gibt praktischerweise am Ende des Import-Prozesses die passenden Redirects aus, die man nur noch in die .htaccess-Datei am Webeserver einfügen muss. Das funktioniert natürlich nur dann, wenn Du dort, wo Deine Website bisher gehostet wird, eine solche .htaccess-Daten bereits hast oder neu anlegen kannst.
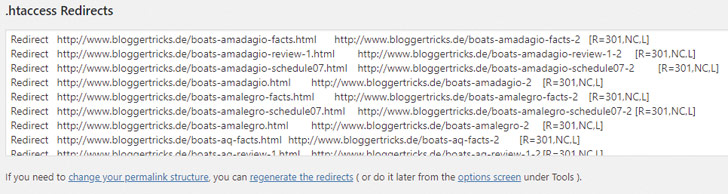
Wenn Du Deine Seiten mit dem Status „draft“ importiert hast, ignoriert das Plugin die Permalink-Einstellungen und generiert die Redirects nach dem WordPress Standard-URL-Schema (?p=853). Gegebenenfalls kannst Du sie so belassen, denn WordPress regelt intern nochmals eine Weiterleitung auf den voreingestellten Permalink. Spielt aber SEO eine größere Rolle für das Blog, dann solltest Du die Weiterleitungen in der Nachbearbeitung der Seiten jeweils nach Veröffentlichung der Seite manuell anpassen. Denn Suchmaschinen reagieren nicht sonderlich wohlwollend auf doppelte Weiterleitungen.
Der Import von bestehendem Content nach WordPress ist meist ein steiniger Weg mit dem einen oder anderen Umweg und Fehlversuch. Dennoch lohnt sich der Aufwand, wenn Du letztlich all Deine Inhalte künftig bequem und zukunftssicher in WordPress verwalten und neue Beiträge hinzufügen kannst. Wir freuen uns auf Deinen Erfahrungsbericht – lass uns wissen, wie Dein Import gelungen ist!
Hole Dir jetzt Dein WordPress-Paket!Teil 2: So erzeugst Du statische HTML-Dateien für den Import
Besteht Deine alte Website bereits aus statischen HTML-Seiten, kannst Du diesen Schritt überspringen und direkt zum Importieren in Teil 3 übergehen. Wahrscheinlich nutzt Du aber auch bisher schon ein Content Management System (CMS), sodass Du statische Seiten draus erst exportieren oder erzeugen musst.
Wichtig: Lege immer zunächst ein Backup der alten Website an, sodass Du alles wiederherstellen kannst, wenn in den kommenden Schritten etwas schief laufen sollte.
Im einfachsten Fall hat das CMS eine HTML-Export-Funktion. Lese dazu am in der Hilfe-Funktion oder Dokumentation des CMS nach, wie man die Export-Funktion nutzt. Wenn das CMS keinen HTML-Export bietet, musst Du ein wenig tricksen und den Content mit einer Desktop-Software grabben – also wie mit einem Browser abrufen und lokal speichern.
Website grabben mit HTTrack
Das beste Tool dafür ist die kostenlose Software HTTrack https://www.httrack.com/, die es für Windows und Linux gibt. Für Mac OSX existiert ein passendes Macport- oder Homebrew-Packages. https://www.httrack.com/page/2/
Die Software ruft die Seiten Deiner alten Website auf wie ein Browser und speichert die dabei erzeugten HTML-Dateien auf Deine Festplatte. Wie Du eine Website mit HTTrack grabbst, findest Du in der folgenden Kurzanleitung, exemplarisch für Windows.
Website grabben mit HTTrack für Windows
Starte WinHTTrack https://www.httrack.com/
Trage einen beliebigen Projektnamen ein.
Lege als Basisverzeichnis einen Ordner auf der Festplatte fest, in dem die HTML-Dateien gespeichert werden sollen
Klicke auf weiter
Wähle die Aktion: Automatische Web-Site-Kopie
Gib unter Web-Adressen die URL der Homepage der zu grabbenden Website ein. Wenn Du möchtest, kannst Du stattdessen auch unter URL-List eine Text-Datei angeben, in der alle zu kopierenden Seiten einzeln als URLs aufgelistet sind. Das ist sehr nützlich, wenn der Grabber aus irgendwelchen Gründen mit den normalen Einstellungen zu viel oder zu wenig Seiten grabbt.
Klicke auf den Button Einstellungen
Wähle den Reiter Filterregeln
Nach einem Klick auf den Button „Einstellungen“ kannst Du im Reiter „Filterregeln“ , bestimmte Datei-Typen und Dateipfade explizit ein- oder ausschließen. Wie das geht, zeigt die Hilfefunktion des Tools direkt in dem entsprechenden Reiter. Gegebenenfalls musst Du hier ein wenig experimentieren, um das gewünschte Ergebnis zu bekommen. Sinnvoll ist, diverse fremde Domains auszuschließen, beispielsweise googlesyndication.com, wenn Du Adsense-Anzeigen auf der Website verwendest. Tipp zum Vorgehen: Probiere dass Grabben erst einmal mit Grundeinstellungen aus. Werden falsche oder zu viele Seiten erfasst, kannst Du im laufenden Betrieb abbrechen, die Filter verfeinern, ergänzen und es erneut probieren.
Wichtig: Im Reiter Struktur wählst Du Strukturtyp = „Site-Struktur (Standard)“ und deaktivierst das Häkchen vor „Keine externen Seiten“. Denn HTTrack klassifiziert alle URLs, die mit einem Domainnamen beginnen, als external, auch Deine eigene Domain – mit dem Ergebnis, dass ausschließlich die Startseite gegrabbt wird.
Bei Grenzwerte und Flusskontrolle kannst Du HTTrack nötigenfalls anweisen, nicht die volle Bandbreite Deines Internet-Zugangs fürs Grabben zu nutzen oder das Grabben auf eine bestimmte Zahl von gleichzeitigen Verbindungen zu drosseln.
Unter dem Reiter Browser ID wählst Du HTML-Fußzeile = none
Klicke jetzt auf weiter und dann auf Fertig stellen.Jetzt beginnt der Grab-Vorgang, der je nah der Größe Deiner Website eine Weile dauern kann.
Wenn HTTrack fertig ist, klicke auf Kopierte Seiten anzeigen. Dann siehst Du im Browser die lokale Kopie der Website, die Du eben gegrabbt hast. Kontrolliere genau, ob alles da ist, was Du brauchst. Achte darauf, dass Du beim Verfolgen von Links in diesen Dateien nicht versehentlich auf der Original-URL im Internet landest und daher fälschlicherweise annimmst, diese Seiten seien lokal vorhanden.
Teil 3: Content-Import mit dem WordPress-Plugin „Import HTML Pages“
In Teil 1 und 2 des Workshops hast Du korrekt formatierte statische HTML-Seiten erzeugt. Jetzt kannst Du den entscheidenden Schritt in Angriff nehmen: den tatsächlichen Import nach WordPress.
Für den eigentlichen Import installierst Du das Plugin „Import HTML Pages“ und aktivierst es. Alle Optionen für den Import findest Du im WordPress-Backend unter Einstellungen – HTML Import.
Lege vor dem Import ein komplettes Backup der WordPress-Installation an. Dann musst Du nach einem unbefriedigend verlaufenen Import lediglich das Backup einspielen und kannst sofort einen neuen Versuch starten.
Alternativ kannst Du aber auch manuell alle zuvor importierten Seiten wieder löschen. Das ist aber nur dann eine brauchbare Alternative, wenn Du nur wenige Seiten importierst.
HTML-Dateien hochladen
Zuvor hast Du die zu importierenden Seiten bereits als statische HTML-Dateien vorbereitet. Diese lädst Du nun per SFTP inklusive eventueller Bilder, die ebenfalls importiert werden sollen, in ein Unterverzeichnis Deines Webspaces hoch. Die Verzeichnisstruktur muss dabei unverändert bleiben.
Der Verzeichnisname spielt dagegen keine Rolle. Die Dateien müssen nur unter derselben Domain abrufbar sein wie das WordPress-Blog, in das Du sie importieren willst.
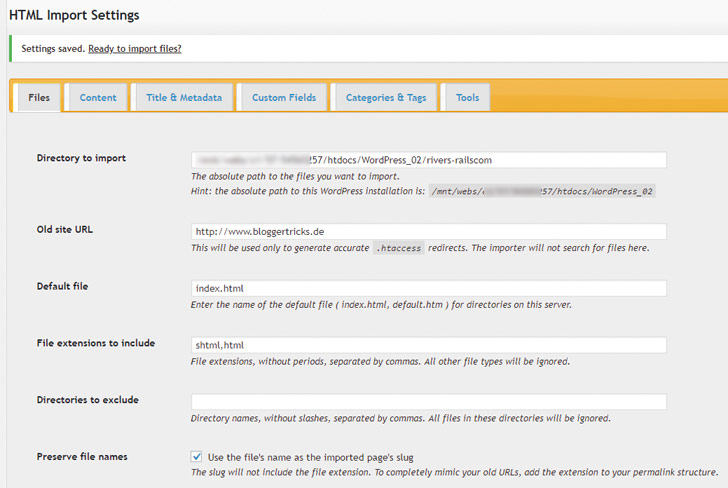
Die wichtigsten Einstellungen
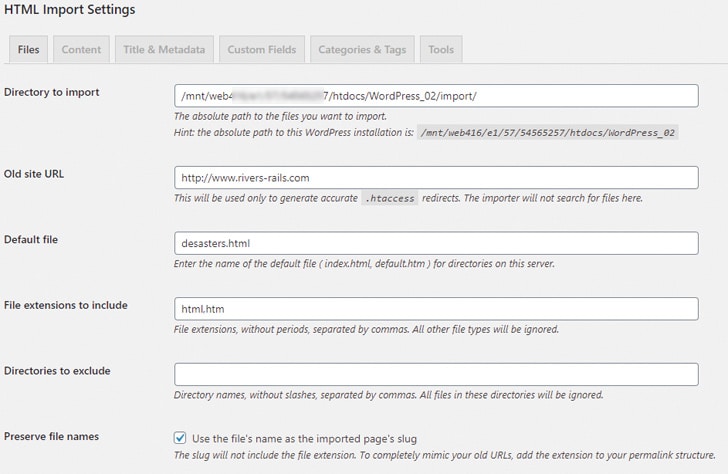
Das Plugin benötigt vor allem in den Reitern Content sowie Title & Metadata die Angabe, welche eindeutigen HTML-Tags den Content beziehungsweise Titel umschließen. Dafür ist ein Blick in den HTML-Quellcode der zu importierenden Dateien nötig. Aber den hast Du ja wahrscheinlich ohnehin schon intensiv bearbeitet, sodass Du Dich da auskennst.<div class=“wp-block-image“><figure class=“aligncenter“><img src=“https://strato.de/blog/wp-content/uploads/2019/01/STRATO_Screenshot_HTML-Import-Settings.jpg“ alt=“Screenshot_Import_Plugin“ class=“wp-image-45733″><figcaption> Optionen für die Erkennung des Contentbereichs der zu importierenden Seiten<br> </figcaption></figure></div>
Ist also in Deinen HTML-Dateien der Seiten-Content beispielsweise mit <div id=“meininhalt“> … </div> umschlossen, trägst Du in den Plugin-Optionen im Reiter Content als Tag div ein, als Attribute id und als Value meininhalt. Genauso gehst Du im Reiter Title & Metadata für den Titel vor.
Sehr wichtig sind die Einstellungen im Reiter Files:
- Directory to import ist das Verzeichnis am Webserver, in dem die zu importierenden HTML-Dateien liegen. Das Plugin ermittelt den Server-Pfad automatisch, sodass Du den vorgegebenen Pfad lediglich um das Verzeichnis ergänzen musst, in dem die zu importierenden Dateien liegen.
- Old Site URL ist die URL, unter der Deine Website bisher zu finden ist – das kann auch dieselbe wie Dein neues WordPress-Blog sein. Das Plugin benutzt die URL, um korrekte Weiterleitungen für die .htacess-Datei nach dem Import zu erzeugen, damit Deine Beiträge weiterhin unter der bisherigen URL erreichbar bleiben beziehungsweise entsprechend weitergeleitet werden.
<ul><li><em>Default file</em> ist die HTML-Datei die bisher als Homepage fungiert hat.</li></ul>
- Files extensions to include beinhaltet alle Dateiendungen von Dateien, die beim Import berücksichtigt werden sollen, oft also: htm oder html, manchmal auch php, shtml oder Ähnliches.
- Preserve file names erhält die Dateinamen der Seiten Deiner alten Website, allerdings ohne Dateiendungen. Falls Du in der Nachbearbeitung Weiterleitungen komplett vermeiden willst und die Seiten unter exakt der gleichen URL abrufbar sein sollen wie vor dem Import, kannst Du das über die Permalink-Struktur von WordPress unter Einstellungen – Permalinks regeln. Aber die richtige Einstellung der Permalink-Struktur bei WordPress ist nochmal ein ganz eigenes Thema für sich.
Tipp: Wenn Du alte Seiten in ein schon bestehendes WordPress-Blog importierst, gehst Du auf Nummer Sicher, wenn Du im Reiter Title & Metadata die Option Set status to auf draft setzt. Dann sind die importierten Beiträge nicht gleich öffentlich und Du kannst Sie noch bearbeiten oder korrigieren, bevor sie live gehen. Der Nachteil dabei: Du musst die Beiträge dann eben auch alle manuell veröffentlichen.
Spätestens wenn alle Plugin-Optionen gesetzt sind, klicke auf Save settings. Zum Import der HTML-Dateien klicke auf Import files. Nach erneutem Bestätigen der Import-Quelle startet der tatsächliche Import mit Klick auf Submit.
Nacharbeit: importierte Seiten prüfen und anpassen
Bevor Du anfängst, die importierten Beiträge oder Seiten zu bearbeiten: Kontrolliere, ob der Import so funktioniert hat, wie Du Dir das vorgestellt hast. Wenn nicht, spiele das Backup ein und probiere es mit entsprechend veränderten Einstellungen noch einmal.
Was nach dem erfolgreichen Import kommt, kann recht aufwändig sein. Denn das Plugin importiert lediglich den Inhalt der Seiten, behebt aber keine Fehler im HTML-Code oder der Content-Struktur, die dort schon vorhanden waren. In vielen Fällen wirst Du daher jede einzelne importierte Seite in WordPress öffnen und überarbeiten müssen. Ein HTML-Validator wie der von W3C oder Freeformatter kann Dir dabei helfen, HTML-Syntaxfehler zu finden.
Anpassungen, die alle importierten Seiten betreffen, hast Du idealerweise schon vor dem Import mit dem oben beschriebenen Suchen-und-Ersetzen-Verfahren vorgenommen. Wenn nicht, gibt es mit SearchReplace von Inpsyde aber auch ein gutes WordPress-Plugin für Suchen-und-Ersetzen-Operationen innerhalb Deiner Beiträge.
Die Sache mit den Permalinks
Gut für Deine Leser und Deine Internetpräsenz ist es, wenn die neuen Seiten weiterhin unter der alten URL erreichbar sind. Am wenigsten aufwendig ist es hierbei, mit permanenten Weiterleitungen zu arbeiten. Für das Google-Ranking ergeben sich daraus keine Nachteile.
Das Plugin gibt praktischerweise am Ende des Import-Prozesses die passenden Redirects aus, die man nur noch in die .htaccess-Datei am Webeserver einfügen muss. Das funktioniert natürlich nur dann, wenn Du dort, wo Deine Website bisher gehostet wird, eine solche .htaccess-Daten bereits hast oder neu anlegen kannst.
Wenn Du Deine Seiten mit dem Status „draft“ importiert hast, ignoriert das Plugin die Permalink-Einstellungen und generiert die Redirects nach dem WordPress Standard-URL-Schema (?p=453). Gegebenenfalls kannst Du sie so belassen, denn WordPress regelt intern nochmals eine Weiterleitung auf den voreingestellten Permalink. Spielt aber SEO eine größere Rolle für das Blog, dann solltest Du die Weiterleitungen in der Nachbearbeitung der Seiten jeweils nach Veröffentlichung der Seite manuell anpassen. Denn Suchmaschinen reagieren nicht sonderlich wohlwollend auf doppelte Weiterleitungen.
Der Import von bestehendem Content nach WordPress ist meist ein steiniger Weg mit dem einen oder anderen Umweg und Fehlversuch. Dennoch lohnt sich der Aufwand, wenn Du letztlich all Deine Inhalte künftig bequem und zukunftssicher in WordPress verwalten und neue Beiträge hinzufügen kannst. Wir freuen uns auf Deinen Erfahrungsbericht – lass uns wissen, wie Dein Import gelungen ist!
Hole Dir jetzt Dein WordPress-Paket!
Franz Neumeier
Ich bin Franz Neumeier, war jahrelang Chefredakteur bei IT-Zeitschriften wie PC Professionell, Internet Professionell und Internet Magazin. Inzwischen habe ich mich als freier Autor vor allem auf Kreuzfahrt-Themen spezialisiert, betreibe mehrere Websites und schreibe für STRATO über verschiedene Themen, vor allem über WordPress und übers Bloggen.
Vivian sagte am
Ich mag das Homepage-Baukasten Editor von Strato, so kann man sehr einfach ein paar Webseiten erstellen. Ich vermissen aber die Möglichkeit, die Webseiten anschließend exportieren zu können (also von Strato ins reine HTML oder von Strato ins WordPress)
Sebastian Thurow sagte am
Hallo Vivian,
erst einmal vielen Dank für Dein positives Feedback!
Zum Website-Export: Diesen Wunsch habe ich an meine Kollegen weitergereicht. Derzeit ist es in der Tat nicht möglich, die gesamten Websites in HTML oder WordPress exportieren zu können.
Die einzige Möglichkeit, die es derzeit gibt, ist das Herunterladen einer statischen Website, die auf unserem Webspace abgelegt wird. Jedoch gehen dann alle dynamischen Inhalte wie Fotogalerien, Anfahrtspläne und Co. verloren.
Das Umwandeln in eine WordPress-Seite geht nicht, da beide CMS auf vollkommen unterschiedlicher Code Basis laufen.
Viele Grüße
Sebastian
Christian Büttner sagte am
Ein sehr lobenswerter Beitrag, aber ich scheue die lange Bearbeitungszeit (meine statische website hat über 1000 Seiten) und die möglichen Risiken.
Gibt es eine Firma oder Privatperson, die einen solchen Auftrag gegen Honorar übernehmen würde?
Sebastian Thurow sagte am
Hallo Christian,
die Möglichkeit gibt es auch bei uns. Über unseren STRATO Design Service kannst Du Deine Website professionell erstellen lassen. Unter dem Link findest Du auch ein Kontaktformular, über das Du einen Rückruf vereinbaren kannst, um Dich telefonisch beraten zu lassen.
Viele Grüße,
Sebastian